Bir haberi hazırlarken genellikle gazetecilerin kaynaklarının kimliğini korumaları gerekir. Başarılı gazetecilik çalışmalarının birçoğu böyle bir yöntemle ortaya konmuştur, ancak kaynağın kişisel güvenliğinin risk altında olduğu durumlarda bir haberde hayati önem taşıyan bilgileri yayınlamak ve arkasındaki kişiyi korumak arasında hassas, koruması zor bir denge var.
Bu zorluklar, çeşitli kaynaklardan, sürekli veri toplamanın mümkün olduğu çağımızda özellikle artmaktadır. Bilişim teknolojilerindeki gelişmeler, büyük hacimli veri işlemeyi mümkün kıldı ve bu da verilerden para kazanma veya verileri gözetim için kullanma gibi eylemlerin ortaya çıkmasına neden oldu. Birçok durumda, bireylerin mahremiyeti temel bir gereklilik olmaktan ziyade bir engel olarak görülmektedir. Yakın tarih, gizlilik ihlali örnekleriyle doludur.
Cambridge Analytica’nın reklam hedefleme için kişisel veri kullanmasından, akıllı cihazlar tarafından gerçekleştirilen istilacı veri takibine kadar birçok örnek sıralamak mümkün. Gizliliğin korunmasına ilişkin beklentiler, devam eden veri sızıntılarının ve veri ihlallerinin ardından zayıflıyor gibi görünüyor.
Her zamankinden daha fazla verinin mevcut ve ulaşılabilir olması nedeniyle gazeteciler, haber yaparken veriye giderek daha fazla güveniyor. Ancak, gizli kaynaklarda olduğu gibi, gereksiz kişisel ayrıntıları ifşa etmeden hangi bilgileri yayınlayacaklarını değerlendirebilmeleri gerekir. Bazı kişisel bilgiler gerekli olabilse de, çoğu hikayenin bir veri setindeki tüm bireylerin tanımlanmasına gerek kalmadan yayınlanması mümkündür. Bu durumlarda, gazeteciler kimlik gizleme veya anonimleştirme olarak bilinen çeşitli yöntemlerle kişilerin mahremiyetini koruyabilir
Kişisel Bilgileri Tanımlama
Kişisel bilgileri neyin oluşturduğunun tanımı, 2000’lerin sonlarında yasal reformlar yoluyla daha resmileşmiş hale gelirken, kasıtlı veya kaza eseri bir veri yayımının bireylerin mahremiyetini tehlikeye atıp atmadığını ortaya çıkarmak uzun süredir gazetecilerin görevi olmuştur. AOL, 2006 yılında milyonlarca çevrimiçi arama sorgusunu yayınladıktan sonra(), gazeteciler, bireylerin sağlık durumları ve ilişki tercihleri de dahil olmak üzere, özel kabul edilebilecek bazı bilgilerin ulaşılabilir hale gelmesi üzerine yalnızca kişilerin arama geçmişlerine dayalı olarak kimlik tanımlamaları yapabilir hale geldiler. Benzer şekilde, Edward Snowden’ın NSA casusluğunun açığa çıkmasının ardından , çeşitli araştırmacılar, iletişim meta verilerinin — cihazlarımız tarafından üretilen bilgiler — kullanıcıları tanımlamak için veya bir gözetleme aracı olarak nasıl kullanılabileceğini gösterdiler.
Ancak, bir haberde kaynak olarak bir veri setini kullanırken, gazeteciler, eldeki bilginin hassasiyetini kendileri değerlendirmek için yeni bir konuma getirilir. Ve bu değerlendirme, neyin kişisel bilgi olup olmadığını anlamakla başlıyor.
Avrupa’da yasal olarak “kişisel veriler” veya diğer bazı diğer bölgelerde “kişisel bilgiler” olarak tanımlanan kişisel olarak tanımlanabilir bilgiler (personally identifiable information — PII) , genellikle bir bireyi doğrudan tanımlayabilen herhangi bir şey olarak anlaşılır, ancak PII’nin tanımlanabilirlik ve duyarlılık bağlamında geniş bir yelpazede var olduğuna dikkat etmek önemlidir. Örneğin, isimler veya e-posta adresleri, tanımlanabilirlik açısından yüksek bir değere sahiptir, ancak paylaşılması genellikle bir kişiyi tehlikeye atmadığı için nispeten düşük bir hassasiyete sahiptir. Konum verileri veya kişisel sağlık kaydı daha düşük tanımlanabilirliğe, ancak daha yüksek derecede hassasiyete sahip olabilir. Örnekleme amacıyla, duyarlılık ve tanımlanabilirlik yelpazeleri boyunca çeşitli PII türlerini çizebiliriz.
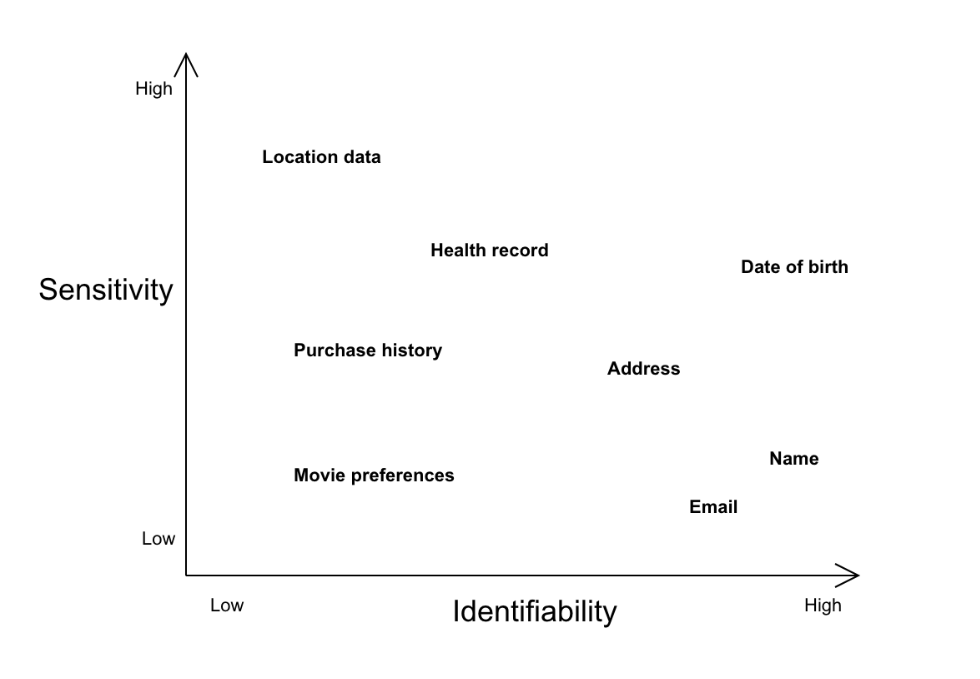
Bilginin kişisel olarak tanımlanabilir veya hassas olma derecesi, hem bağlama hem de veri karıştırmanın birleştirme etkisine bağlıdır. Bir kişinin adı, Facebook hayranların veri kümesinde düşük risk taşıyabilir, ancak adı siyasi muhalifler listesinde yer alıyorsa, bu bilgileri yayınlama riski önemli ölçüde artar. Bilginin değeri de diğer verilerle birleştirildiğinde değişir. Satın alma geçmişini içeren bir veri kümesinin kendi başına herhangi bir kişiye bağlanması zor olabilir; ancak, konum bilgisi veya kredi kartı numaraları ile birleştirildiğinde, hem tanımlanabilirlik hem de hassasiyet açısından daha yüksek derecelere ulaşabilir.
Avustralya Sağlık Bakanlığı 2016 yılında, sadece akademisyenlerin kimliksizleştirilmiş alanlardan birini görüntüleyebileceği bir eczacılık veri seti yayınladı. Bunun üzerine, kişisel bilgilerin açığa çıkması ihtimali gerekçe gösterilerek, Avustralya Bilgi Ofisi (Office of the Australian Information Commissioner) tarafından soruşturma açıldı.
Başka bir örnekte, profesyonel tenisçiler arasındaki dolandırıcılığı araştıran Buzzfeed gazetecileri, 2016 yılında raporlamada kullandıkları anonim verileri yayınladı. Ancak bir grup lisans öğrencisi, halka açık verileri kullanarak etkilenen tenis oyuncularını yeniden belirleyebildi. Bu örneklerin gösterdiği gibi, bir gazetecinin bir veri kümesinin kişisel niteliğini belirleme yeteneği, hem içerdiği bilgilerin hem de halihazırda halka açık olan bilgilerin dikkatli bir şekilde değerlendirilmesini gerektirir.

Kimlik Gizleme Nedir?
Bir kaynağın kimliğini gizlemek için, bir gazeteci anonimlik çıkarabilir veya takma ad kullanabilir. Watergate skandalında Derin Boğaz (Deep Throat) buna örnek gösterilebilir.
Veriler ve enformasyonla çalışırken, kişisel ayrıntıları kaldırma sürecine kimlik gizleme veya bazı yargı alanlarında anonimleştirme adı verilir. İnternetten çok önce, veri kimlik gizleme teknikleri gazeteciler tarafından, örneğin sızdırılan belgelerdeki isimleri yeniden düzenleyerek kullanıldı. Günümüzde gazeteciler, dijital ortamlarda mahremiyeti korumak için yeni kimlik gizleme yöntemleri ve araçlarıyla donanmış durumdalar, bu da daha büyük miktarda veriyi analiz etmeyi ve değiştirmeyi kolaylaştırıyor.
Verilerin kimlik bilgilerinin kaldırılmasının amacı, olası yeniden tanımlamadan kaçınmak, başka bir deyişle verileri anonimleştirerek bir bireyi tanımlamak için kullanılamamaktır. Veri anonimleştirmenin bazı yasal tanımları mevcut olmakla birlikte, kimlik gizliliğinin düzenlenmesi ve uygulanması genellikle geçici, sektöre özgü bir temelde ele alınır. Örneğin, Amerika Birleşik Devletleri’ndeki sağlık kayıtları, veriler kamu tüketimi için yayınlanmadan önce; isimler, adresler ve sosyal güvenlik numaraları gibi doğrudan tanımlayıcıların anonimleştirilmesini gerektiren, Sağlık Sigortası Taşınabilirlik ve Sorumluluk Yasası (HIPAA) ile uyumlu olmalıdır.
Avrupa Birliği’nde ise Genel Veri Koruma Yönetmeliği (GDPR), hem adlar, adresler ve e-postalar gibi doğrudan tanımlayıcıların hem de iş unvanları ve posta kodları gibi dolaylı tanımlayıcıların anonimleştirilmesini zorunlu kılar.
Gazeteciler, hikayelerini geliştirirken hangi bilgilerin bir haber için hayati önem taşıdığına ve nelerin ihmal edilebileceğine karar vermelidir. Çoğu zaman, bir bilgi parçası ne kadar değerli olursa, o kadar hassas olur. Örneğin, sağlık araştırmacılarının teşhis veya diğer tıbbi verilere erişebilmeleri gerekir, ancak bu veriler belirli bir bireyle bağlantılıysa yüksek derecede hassasiyete sahip olabilir. Gazeteciler, neyin yayınlanacağına karar verirken, verilerin kullanışlılığı ile duyarlılığı arasında doğru dengeyi sağlamak için bir dizi kimlik gizleme tekniği arasından seçim yapabilirler.
Veri Redaksiyonu
Bir veri setinin kimliğini gizlemenin en basit yolu, herhangi bir kişisel veya hassas veriyi kaldırmak veya redakte etmektir. Açık bir dezavantaj, verilerin bilgilendirici değerinin olası kaybı olsa da, redaksiyon en yaygın olarak, genellikle bir hikayenin temelini temsil etmeyen adlar, adresler veya sosyal güvenlik numaraları gibi doğrudan tanımlayıcılar üzerinde kullanılır.
Bununla birlikte, teknolojik ilerlemeler ve artan veri kullanılabilirliği, dolaylı tanımlayıcıların tanımlanabilirlik potansiyelini artırmaya devam edecek, bu nedenle gazeteciler tek kimlik gizleme yöntemi olarak veri redaksiyonuna güvenmemelidir.
Takma İsim Kullanma
Bazı durumlarda, bilgilerin tamamen kaldırılması verilerin kullanışlılığını sınırlar. Takma isim kullanımı, tanımlanabilir verileri rastgele veya bir algoritma tarafından oluşturulan takma adlarla değiştirerek olası bir çözüm sunar. Takma isimlendirme için en yaygın teknikler şunlardır: karma oluşturma (hashing) ve şifreleme (encryption).
Karma oluşturma (hashing), verileri okunamayan karmalara dönüştürmek için matematiksel işlevlere dayanır. Öte yandan şifreleme, verilerin iki yönlü algoritmik dönüşümüne dayanır. İki yöntem arasındaki temel fark, şifrelenmiş verilerin şifresinin doğru anahtarla çözülebilmesi, ancak karma bilgilerin geri alınamamasıdır. MySQL ve PostgreSQL gibi birçok veritabanı sistemi, verilerin hem karılmasını hem de şifrelenmesini sağlar.
Takma isimlendirme, Uluslararası Araştırmacı Gazetecilik Merkezi (ICIJ) tarafından yapılan Offshore Sızıntıları soruşturmasında önemli bir rol oynadı. İşlenmesi gereken çok büyük veri hacmi göz önüne alındığında, gazeteciler, sızdırılan belgelerde görünen her birey ve varlıkla ilişkili benzersiz kodlara güvendiler. Bu takma isimli kodlar, bireylerin ve tüzel kişilerin adlarının eşleşmediği durumlarda bile sızdırılan belgeler arasındaki bağlantıları göstermek için kullanıldı.
Bilgi, ek veri kullanılmadan artık bir bireye bağlanamıyorsa takma isimlendirme olarak kabul edilir. Fakat aynı zamanda, takma isim verilen verileri diğer veri kümeleriyle birleştirme olasılığı, takma isimlendirmeyi muhtemelen zayıf bir kimlik gizleme yöntemi haline getirecektir. Bir veri kümesi boyunca aynı takma ismi tekrar tekrar kullanmakla bile, takma ismin her geçtiği yerde değişkenler arasındaki ilişkileri bulma potansiyeli büyür ve yöntemin etkinliği azalabilir. Son olarak, bazı durumlarda, takma adlar oluşturmak için kullanılan algoritmalar üçüncü şahıslar tarafından () kırılabilir doğal güvenlik açıklarına sahiptir. Bu nedenle, gazeteciler kişisel verileri gizlemek için takma isimlendirme kullanırken dikkatli olmalıdır.
İstatistiksel Gürültü
Hem veri redaksiyonu hem de takma isimlendirme yeniden tanımlama riski taşıdığından, genellikle k-anonimleştirme (https://en.wikipedia.org/wiki/K-anonymity) gibi istatistiksel gürültü yöntemleriyle birleştirilirler. Bunlar, en azından belirli sayıda bireyin aynı dolaylı tanımlayıcıları paylaşmasını sağlayarak yeniden tanımlama sürecini engeller. Güvenilirliği yeterli seviyeye ulaştırmak için, benzersiz tanımlayıcı kombinasyonlarına sahip en az 10 giriş olmalıdır. Bir veri kümesine istatistiksel gürültü eklemek için yaygın tekniklerden bazıları, bir ülkenin adını bir kıtayla değiştirmek veya sayıların aralıklara dönüştürülmesidir. Ek olarak, veri çıkarma ve takma adlandırma, bir veri kümesinde benzersiz tanımlayıcı kombinasyonlarının bulunmadığından emin olmak için genellikle istatistiksel gürültü teknikleriyle birlikte kullanılır. Aşağıdaki örnekte, belirli sütunlardaki veriler, tek tek girişlerin yeniden tanımlanmasını önlemek için genelleştirilir veya yeniden düzenlenir.
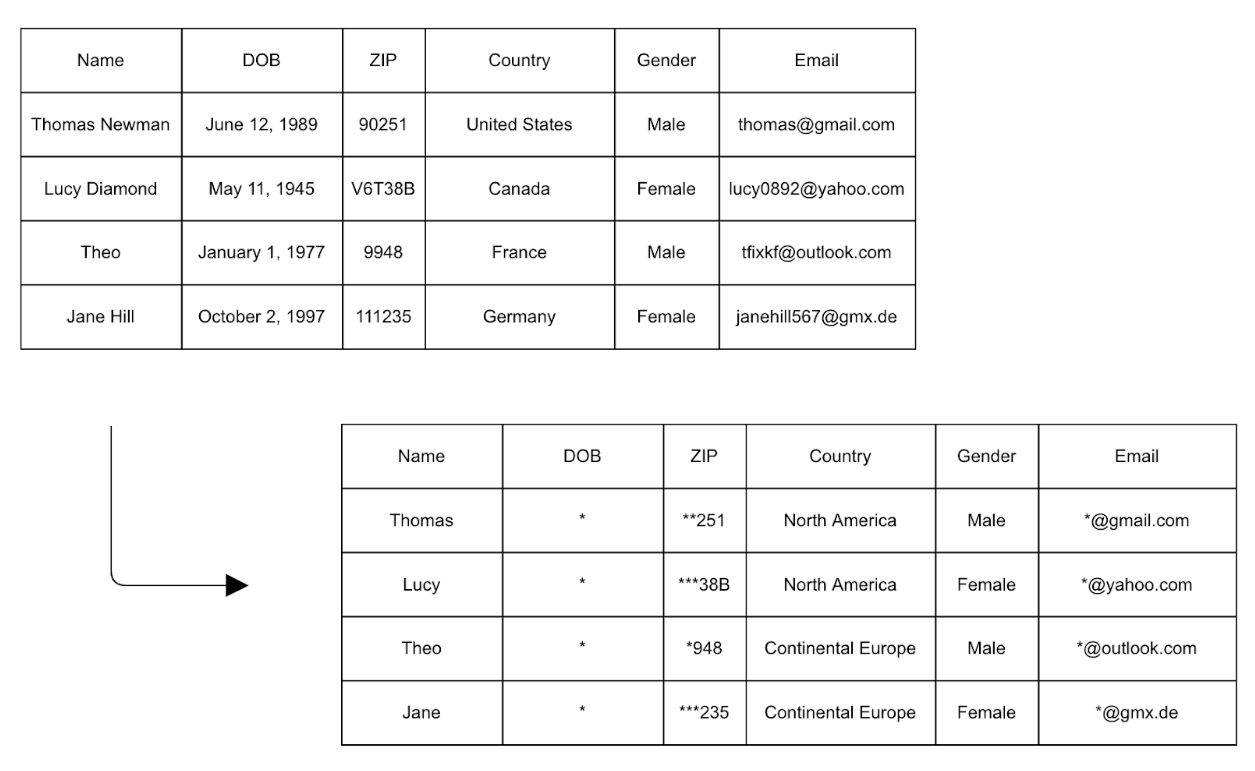
Veri Seçme
İşlenmemiş verilerin bütünlüğünün korunması gerekmediğinde, gazeteciler kimlik gizleme yöntemi olarak veri toplamaya güvenebilirler. Veri kümesinin tamamını yayınlamak yerine, veriler, herhangi bir doğrudan veya dolaylı tanımlayıcıyı atlayan özetler şeklinde yayınlanabilir. Veri toplamayla ilgili dikkat edilmesi gereken temel konu, toplanan verilerin en küçük bölümlerinin, bireylere dair belirli verileri açığa çıkarmayacak büyüklükte olmasını sağlamaktır. Bu özellikle, toplanan veriler birden çok boyutu birleştirilebildiği zaman geçerlidir.
Kimlik Gizleme Akışları
Son teslim tarihi olan gazeteciler için kimlik gizleme, veri kalitesini değerlendirme veya bir veri kümesinin nasıl görselleştirileceğine karar verme gibi daha önemli kararlar için ikincil öncelikli gibi görünebilir. Ancak, bireylerin mahremiyetinin sağlanması yine de gazetecilik sürecinde sağlam bir yere sahip olmalıdır, çünkü özellikle kişisel verilerin uygunsuz şekilde kullanılması haberin güvenilirliğini zayıflatabilir. Gizlilik yasaları kapsamındaki yasal sorumluluk, yayının veri toplama veya işlemeden sorumlu olması durumunda da endişe yaratabilir. Bu nedenle, veri gazetecileri kimlik gizliliğini iş akışlarına dahil etmek için aşağıdaki adımları atmalıdır:
Veri setim kişisel bilgiler içeriyor mu?
Birlikte çalıştığınız veri setinin hava durumu verilerini veya herkese açık spor istatistiklerini içermesi, sizi kimlik gizleme konusunda endişelenme ihtiyacından kurtarabilir. Diğer durumlarda, isimlerin veya sosyal güvenlik numaralarının varlığı, herhangi bir gizlilik riskini hızlıca gündeme getirecektir. Bununla birlikte, çoğu zaman, verilerin kişisel olarak tanımlanabilir olup olmadığının belirlenmesi daha yakından incelemeyi gerektirebilir. Susan McGregor ve Alice Brennan’ın bu uzun yazısında açıklandığı üzere bu özellikle sızan verilerle çalışırken geçerlidir. Doğrudan tanımlayıcıların varlığına dikkat çekmenin yanı sıra, gazeteciler IP adresleri, iş bilgileri ve coğrafi kayıtlar gibi dolaylı tanımlayıcılara da çok dikkat etmelidir. Genel bir kural olarak, bir kişiyle ilgili herhangi bir bilgi gizlilik riski olarak değerlendirilmeli ve buna göre işlenmelidir.
Veriler ne kadar hassas ve tanımlanabilir?
Kişisel bilgiler, diğer verilerle birleştirilip birleştirilemeyeceği başta olmak üzere içinde bulunduğu bağlama göre farklı riskler taşır. Bu, gazetecilerin iki şeyi değerlendirmesi gerektiği anlamına gelir: 1) bir veri parçasının ne kadar tanımlanabilir olduğu ve 2) bir bireyin mahremiyetine ne kadar duyarlı olduğu. Kendinize şu soruyu sormalısınız: Bir bireyin hikayeyle ilişkisi onun güvenliğini veya itibarını tehlikeye atar mı? Eldeki veriler, bir bireyin kimliğini açığa çıkarabilecek diğer mevcut veri kümeleriyle birleştirilebilir mi? Öyleyse, bu verileri yayınlamanın faydaları, o bilgiye ilişkin gizlilik risklerinden ağır basıyor mu? Kişisel ayrıntıları ifşa etmenin gizlilik riskleri ile yayıncılıktaki kamu çıkarını dengelemek için duruma göre bir yaklaşım geliştirmek gereklidir.
Veriler nasıl yayınlanacak?
İnternet öncesi dönemde bir basılı yayın için yazan bir gazetecinin, verilerin nasıl açıklanacağı konusunda endişelenmesine gerek yoktu, çünkü basılı grafikler ve istatistikler, temeldeki verilerin sorgulanmasına pek izin vermiyordu. Bununla birlikte, günümüz veri gazeteciliğinin en ileri noktasında, karmaşık araçlar ve etkileşimli görselleştirmeler, haberin tüketicilerinin belirli bir hikayede kullanılan verilerin ayrıntılı bir incelemesini yapmasına olanak tanır. Örneğin, birçok gazeteci, GitHub’da paylaşılan kod ve verilerle açık kaynaklı bir yaklaşımı tercih ediyor. Gizliliği göz önünde bulundurarak kaynak açmak için, tüm verilerin kişisel bilgilerden dikkatlice temizlenmesi gerekir. Görselleştirmeler söz konusu olduğunda, bazı gazeteciler, orijinal veri kümesini gizleyen önceden toplanmış verilerden yararlanarak gizliliği korur. Ancak bu birleştirilmiş örneklerin minimum tanımlanabilirlik eşiğini aşıp aşmadığını kontrol etmek önemlidir.
Verileriniz için hangi kimlik gizleme tekniği doğru?
Gazetecilerin, eldeki verilere en iyi şekilde uyması için çoğu kez kimlik gizleme tekniklerinin bir kombinasyonunu kullanmaları gerekecektir. Doğrudan tanımlayıcılar için, veri redaksiyonları ve takma adlandırma — uygun şekilde uygulanırsa — genellikle bireylerin mahremiyetinin korunmasında yeterlidir. Dolaylı tanımlayıcılar için, verileri kümeler halinde gruplandırarak veya hikaye için hayati olmayabilecek bilgileri genelleştirerek bazı istatistiksel parazitler eklemeyi düşünün. Veri toplama, son derece hassas veriler için en iyi seçenektir, ancak gazetecilerin, hiçbir kişisel bilginin yanlışlıkla açığa çıkmamasını sağlamak için, yeterince geniş bir veri yelpazesi ve toplanan değişkenlerde yeterince tekdüze dağılım olmasını sağlamaları gerekir.
Örnek Olmak
Veriler çevrimiçi olarak mevcut olduğunda, revizyon veya düzeltme imkanı yoktur. Veri kümenizin her türlü kişisel ayrıntıdan arındırıldığını düşünseniz bile, birilerinin verilerinizi başka bir kaynakla birleştirerek bireyleri yeniden tanımlamasına veya takma isimlendirme algoritmanızı kırıp içerdiği kişisel bilgileri ifşa etmesine ilişkin bir risk daima kalır. Her zaman olduğu gibi, verileri birleştirmenin ve dönüştürmenin beklenmedik yollarını mümkün kılan makine öğrenimi ve örüntü tanıma gibi yeni teknolojilerin geliştirilmesiyle yeniden tanımlama riskleri artmaya devam edecek.
Görünüşte kişisel olmayan veri noktalarının, doğru verilerle birleştirildiğinde tanımlama amacıyla kullanılabileceğini unutmayın. Netflix, en iyi öneri algoritması için kötü şöhretli Netflix ödülünü duyurduğunda, mevcut veriler tüm kişisel tanımlayıcılardan arındırıldı. Ama yine de, araştırmacılar “anonimleştirilmiş” Netflix veri kümesindeki kişileri tanımlamak için IMDb.com ve diğer çevrimiçi kaynaklardan alınan verilerle kişisel film tercihlerini çapraz referanslamayı başardı.
Günümüzün kimlik gizleme yöntemlerinin sınırlamalarına rağmen, gazeteciler, bireylerin mahremiyetini koruma çabalarında her zaman gayretli olmalıdır. Örnek olarak; ICIJ, büyük hacimli kişisel verileri gizliliği ön planda tutarak işler. Panama Belgeleri hakkında haber yaparken, gazeteciler John Doe takma adını kullanarak hem sızıntının kaynağının anonimliğini korudu hem de gizli bilgilerin sızdırılan belgelerde nasıl yayınlanacağını dikkatlice değerlendirdi. Her geçmişten gazetecinin, haberciliklerinde mahremiyet ile kamu menfaati arasında bir denge kurmak için benzer adımlar atamamaları için hiçbir neden yok.
Ayrıca, gizlilik konusunda bilinçli adımlar atılmadığında Ashley Madison [evlilik dışı flört web sitesi] sızıntısıyla kişisel verilerin ifşa edilmesinden kaynaklanan kişisel trajedilerden Wikileaks ile ilişkili hassas verilerin büyük ölçüde açığa çıkmasına birçok olası sorun örneği vardır. Veri muhabirleri aynı tuzaklardan kaçınmaya çalışmalı ve bunun yerine her zaman raporlarında sorumlu veri uygulamalarını teşvik etmelidir.
Çeviri: Berke Kesici, VOYD üyesi ve gönüllüsü
Orijinal Metin: https://gijn.org/2020/10/20/how-data-journalists-can-use-anonymization-to-protect-privacy/